


音频数字信号有几个需要我们关注的基础属性,分别是采样率、采样位深和声道数,下面一一介绍。
1 采样率
音频采样率,指的是单位时间内(1s)对声音信号的采样次数(参考数字化过程-采样)。常说的 44.1KHz 采样率,也即 1 秒采集了 44100 个样本。
我们前面了解到,采样率越高、采样点越多,就可以越好地表示原波形,这就是采样率的影响。而更详细的说明,可以参考奈奎斯特采样定理:采样率 f,必须大于原始音频信号最大振动频率fmax 的 2 倍(也即 f > 2*fmax,fmax 被称为奈奎斯特频率),采样结果才能用于完整重建原始音频信号;如果采样率低于 2*fmax,那么音频采样就存在失真。比如,要对最高频率fmax=8KHz 的原始音频进行采样,则采样率 f 至少为 16KHz。
对于最大频率为 f 的音频信号,当我们分别采用 f、2f、4f/3 的采样率进行采样时,所得到的采样结果参考下图。显然,只有当采样率为 2f 时,才能有效地保留原信号特征。采样率 f 和3f/4 下得到的结果,都和原波形差别很大。
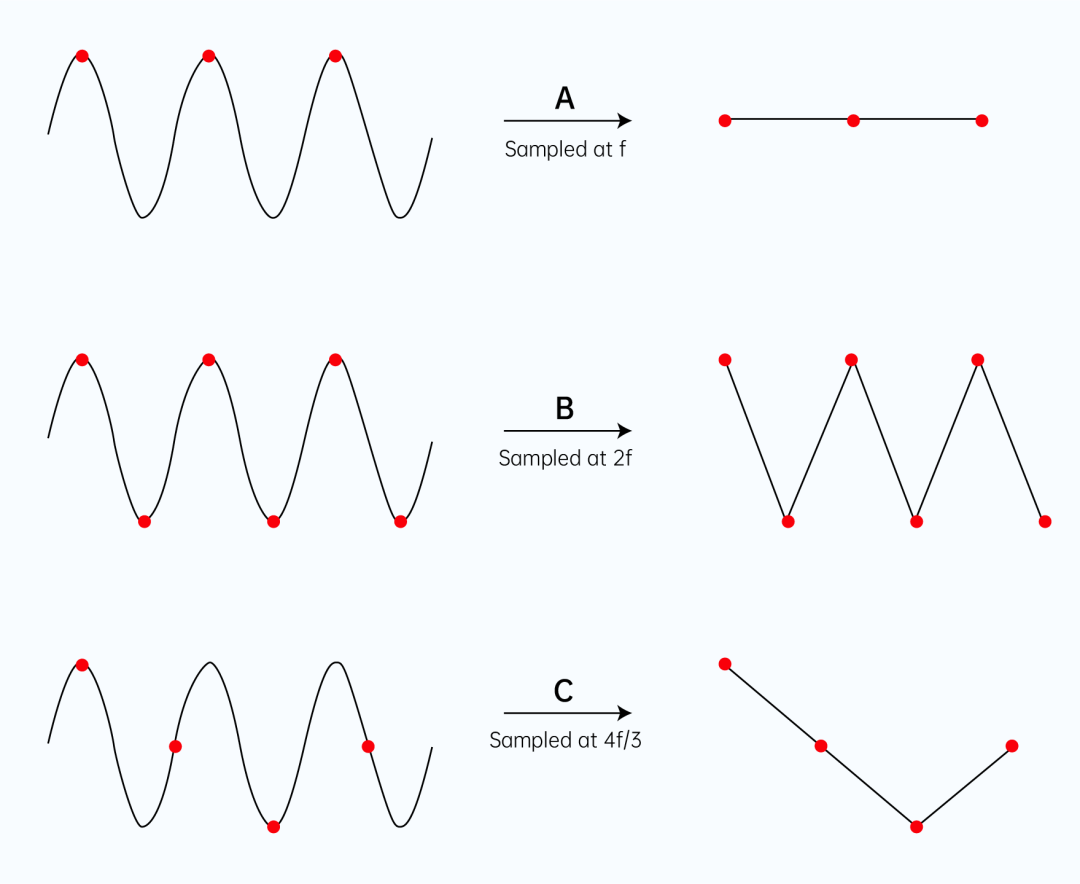
那么,我们需要多大的采样率?
按前面的讨论,采样率似乎越大越好,是否如此呢?理论上来说,最低采样率需要满足奈奎斯特采样定理,在该前提下,采样率越高则保留的原始音频信息越多,声音自然就越真实。但需要注意的是,采样率越高则采样得到的数据量越大,对存储和带宽的要求也就越高。在实际应用中,我们为了平衡带宽和音质,不同场景往往会有不同的选择。常见的选择如下:

从上面的示例,我们发现,当采样率从 8KHz 翻倍至 16KHz 时,听感明显变得更清晰、空灵和舒适。此时,采样率的提升带来了明显的音质提升。而采样率从 16KHz 提升至 44.1KHz 时,实际听感却好像没有太大的变化,这是因为采样率到达一定程度后,音频质量已经比较高,再往上提升带来的优化已经很细微。 借助专业的频谱分析软件,或许可以观察到高频谱区域的能量差异,但对于人耳来说,已经很难进行区分。所以实际应用中,我们不需要一味追求高采样率,而是要综合带宽、性能、实际听感,选择合适的配置即可。
ZEGO-SDK 使用什么采样率?
在实际应用中,采集 → 前处理 → 编码等过程所使用的采样率并非一成不变的,首先受限于实际物理设备能力,然后需要符合软硬件前处理、编码算法的要求,中间会涉及到采样率的转换,最终以编码采样率为最终的输出。
ZEGO-SDK 为满足各种 RTC 场景需求,支持了 8KHz~48KHz 的全频带音频采样率,并经过实践验证选用了最符合自研算法效率、音质调优的默认配置。处理过程中 SDK 音频引擎会根据需要自行完成采样率转换,开发者无需操心。ZEGO-SDK 默认使用 44.1KHz 的采集采样率,而编码采样率使用 44.1KHz 或 48KHz(依据编码格式不同,一般 OPUS 编码使用 48KHz,AAC 编码使用 44.1KHz);针对某些特殊需求,比如希望兼容定制设备、或者有苛刻的带宽限制,ZEGO-SDK 也提供了进阶接口,允许配置使用低采样率(8KHz 及以上)。
2 采样位深
我们在学习音频数字化过程的“量化”步骤时,就提及了量化精度-位深的概念。采样位深,指的是在音频采集量化过程中,每个采样点幅度值的取值精度,一般使用bit作为单位。
比如,当采样位深为 8bit,则每个采样点的幅度值可以用 2^8=256 个量化值表示;采样位深为 16bit 时,则每个采样点的幅度值可以用 2^16=65536 个量化值表示。显然,16bit 比 8bit 可存储、表示的数据更多、更精细,量化时产生的误差损失就越小。位深影响声音的解析精度、细腻程度,我们可以将其理解为声音信号的“分辨率”,位深越大,音色也越真实、生动。
采样位深选择
和采样率的选择类似,虽然理论上来说位深越大越好,但是综合带宽、存储、实际听感的考虑,我们应该为不同场景选用不同的位深。

ZEGO SDK 在音频采样过程中使用的位深是 16bit(取决于实际的设备能力),这符合 RTC 场景对音质、带宽压力的综合需求。
3 声道数
相对于采样率和位深,接下来要讨论的声道数,大家应该比较熟悉。我们常说的单声道、双声道,其实就是在描述一个音频信号的声道数(分别对应于声道数 1 和 2)。声波是可以叠加的,音频的采集和播放自然也如此,我们可以同时从多个音频源采集声音,也可以分别输出到多个扬声器,声道数一般指声音采集录制时的音源数量或播放时的扬声器数量。
除了常见的声道数1、2,PC上还有4,6,8等声道的扩展。一般来说声道数越多,声音的方向感、空间感越丰富,听感也就越好。目前很多手机厂商已经将双声道扬声器作为旗舰标配。在RTC音乐场景,越来越多的应用也开始采用双声道配置,其目的也是进一步提高听感,给用户更好的体验。
声道数的选择
实时音视频场景下,声道的选择受限于编解码器、前处理算法的能力,一般仅支持单、双声道。而双声道配置主要在语音电台、音乐直播、乐器教学、ASMR 直播等场景使用,其它场景单声道即可满足。
当然,最终能否使用哪一种声道配置,还是由实际采集、播放设备的能力决定。解码音频数据时,可以获取数据的声道数,在实际播放时,也要先获取设备属性。如果设备支持双声道,但待播放数据是单声道的,就需要将单声道数据转成双声道数据再播放;同理,如果设备只支持单声道,但数据是双声道的,也需要将双声道数据转换成单声道数据再播放。
ZEGO-SDK使用什么声道数?
ZEGO SDK 的音频采集、编码默认使用单声道,在 Android、iOS、Windows 等平台也实现了双声道配置,开发者可以通过 API 灵活选择。但需要注意的是,和采样率一样,在实际应用中声音道数也是会变化的,仅仅通过 SDK 接口设置双声道采集/编码还不够,我们还需要支持双声道的设备和系统配合,才能实现期望的双声道效果。
我们现在已经了解了采样率、采样位宽、声道数的基本概念和影响,也知道实际应用中这些配置是可变的。那么有一个问题,如果我们使用不匹配的参数对音频进行处理,处理前后没有进行正确的转换,会有什么影响呢?
音频码率
前面我们谈到,数字音频的三要素不仅影响音频质量,也会影响音频存储、传输所需的空间、带宽。而实际应用场景下,音质决定用户体验、带宽决定成本,都是我们必须考虑到。音质可能更多是主观上的感受,但带宽、空间是比较容易量化的,我们需要了解音频码率的概念。
音频码率,又称为比特率,指的是单位时间内(一般为1s)所包含的音频数据量,可以通过公式计算。比如采样率 44.1K Hz,位深16bit的双声道音频PCM数据,它的原始码率为:
原始码率 = 采样率/s x 位深/bit x 声道数 x 时长(1s)
44.1 * 1000 * 16 * 2 * 1 = 1411200 bps = 1411.2 kbps = 1.411 Mbps (需要注意单位之间的差异和转换,b=bit)
如果一个PCM文件时长为1分钟,则传输/存储这个文件需要的数据量为:1.411 Mbps * 60s = 86.46Mb
需要注意的是,上述计算结果是未经压缩的、原始音频PCM数据的码率。RTC场景下,往往还需要再使用 AAC、OPUS 等编码算法做编码压缩,进一步减小带宽、存储的压力。码率的选择也是一个综合质量和成本的博弈,以后我们会详细讲解音频编码的知识,此处大家先了解即可。



