


随着线上泛娱乐的兴起,语聊房、在线 KTV 以及直播等场景在人们的日常生活中占据越来越重要的地位,用户对于音质的要求也越来越高,因此超越传统语音降噪算法的 AI 降噪算法应运而生,所以目前各大 RTC 厂商普遍使用 AI 技术进行降噪处理,使用 AI 降噪技术消除除人声外的一切声音。
但对于一些特殊场景,如在线 KTV、线上直播等声卡场景,或者弹唱、伴奏、乐器等使用场景中,我们可以明显的感受到,一般降噪处理或 AI 降噪处理的过程中会将音乐/伴奏误识别为噪音,并进行降噪处理,给用户带来很不好的线上体验。因此,在此类使用场景中用户越来越不满足于背景降噪,而是提出更高要求,那就是深度降噪的同时保留音乐的音质。为了满足用户消噪与音乐音质高保真的需求,ZEGO 即构科技自研了一套自适应降噪方案,能在音乐与非音乐场景中智能切换,既保证了无音乐场景下的语音的质量,又保留了音乐的高保真音质。
音乐场景降噪方案简介
首先简单了解一下即构音乐场景降噪的方案流程:
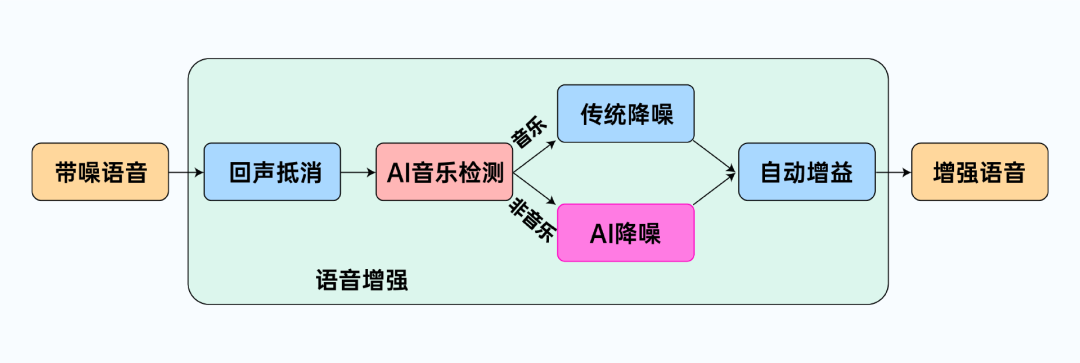
从图中可以看到,经过前处理后的音频数据会被送入 AI 音乐检测模块,接着根据检测结果将场景分为音乐和非音乐场景。若检测出音乐场景则会使用传统降噪对音频数据进行处理,以减少对音乐的损伤,非音乐场景则继续使用 AI 降噪进行更深度的噪声消除。最后数据会经过自动增益模块完成最终的语音增强。
关于 AI 音乐检测算法
由上文描述中可以看到,完成音乐场景降噪功能最重要的一环就是 AI 音乐检测算法。为了满足音乐场景的实时切换与极高检测率的需求,我们自研了基于AI的音乐检测算法 ZegoAIMusicDetecion。 算法流程如下:
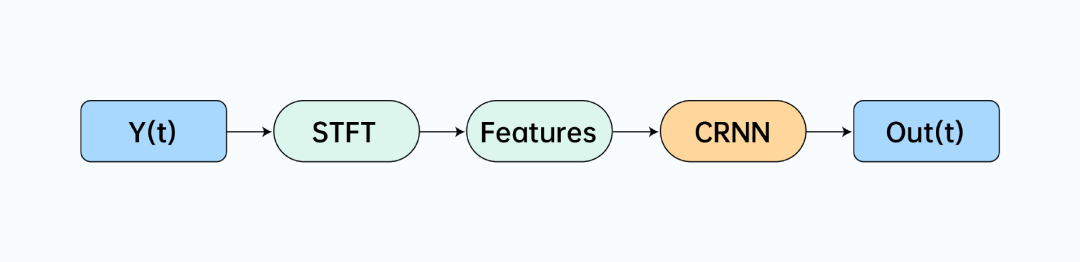
我们对数据进行帧长为 20ms,帧移为 10ms 的 STFT 处理后,使用 Bark 频带尺度将数据分为8 个子带,再分别求取一阶差分,二阶差分和谱平坦度最终得到 25 维特征。将计算得到的特征送入到我们设计的轻量型网络模型 CRNN,模型结构如下:
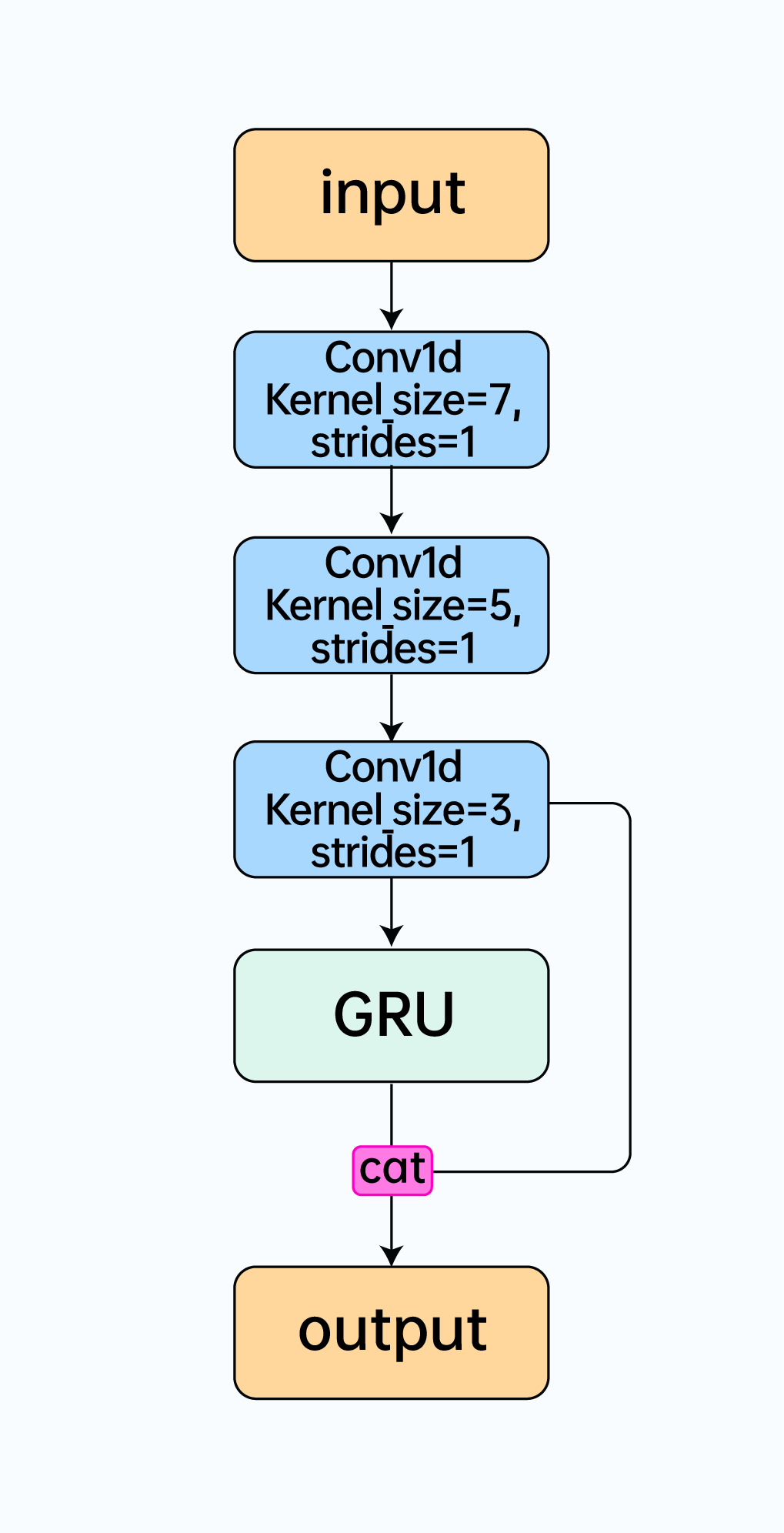
这里使用多层 Conv1d 卷积层能进一步的对特征进行提取。训练时,我们搜集了大量的开源音乐、语音与噪声数据进行训练,同时使用不同信噪比进行数据混合增强,确保模型有足够的泛化性。在训练优化器上,我们选择了 AdamW 以更好地对模型进行正则化处理,学习率为 0.001,批大小是 64,损失函数我们使用了交叉熵函数,公式如下:
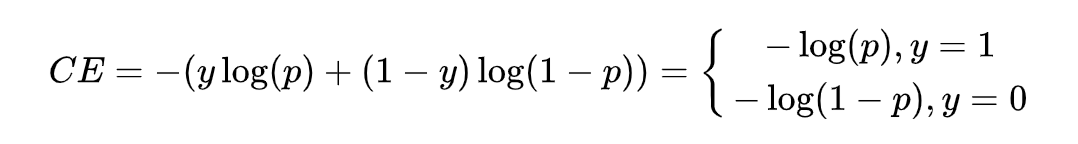
算法效果与性能开销
有了 AI 音乐检测算法的帮助,我们最终可以实现针对音乐场景的降噪方案,方案最终的效果如下:

从上面的频谱图以及实际的听感来看,都可以直观的感受到即构音乐场景降噪方案对音乐音质的保护。在提供良好效果的同时,ZegoAIMusicDetecion 秉承着极轻量级模型的设计理念,整体计算量大约为 1.2M FLOPS,RTF 指标在各个平台和终端上均控制在 0.2% 以内。在此基础上,我们采用多帧平滑的后处理技术使音乐检测误检率低于 1%,音乐检测率达到 95% 以上。
技术展望
音乐场景在泛娱乐社交和互动中十分常见,需要注重用户和听众的使用感觉,做好音乐场景降噪处理。综上所述,ZEGO 即构科技为了同时兼顾降噪与音乐音质体验,自研了基于 AI 的音乐检测算法,设计出一套音乐场景降噪方案,充分体现即构对于用户良好体验的高度重视。未来,我们会结合具体行业和场景,引入更多的可行性方案,提升产品的场景适应能力,给用户提供更好的音频体验!




