

实时互动升级季 核心产品限时特惠 
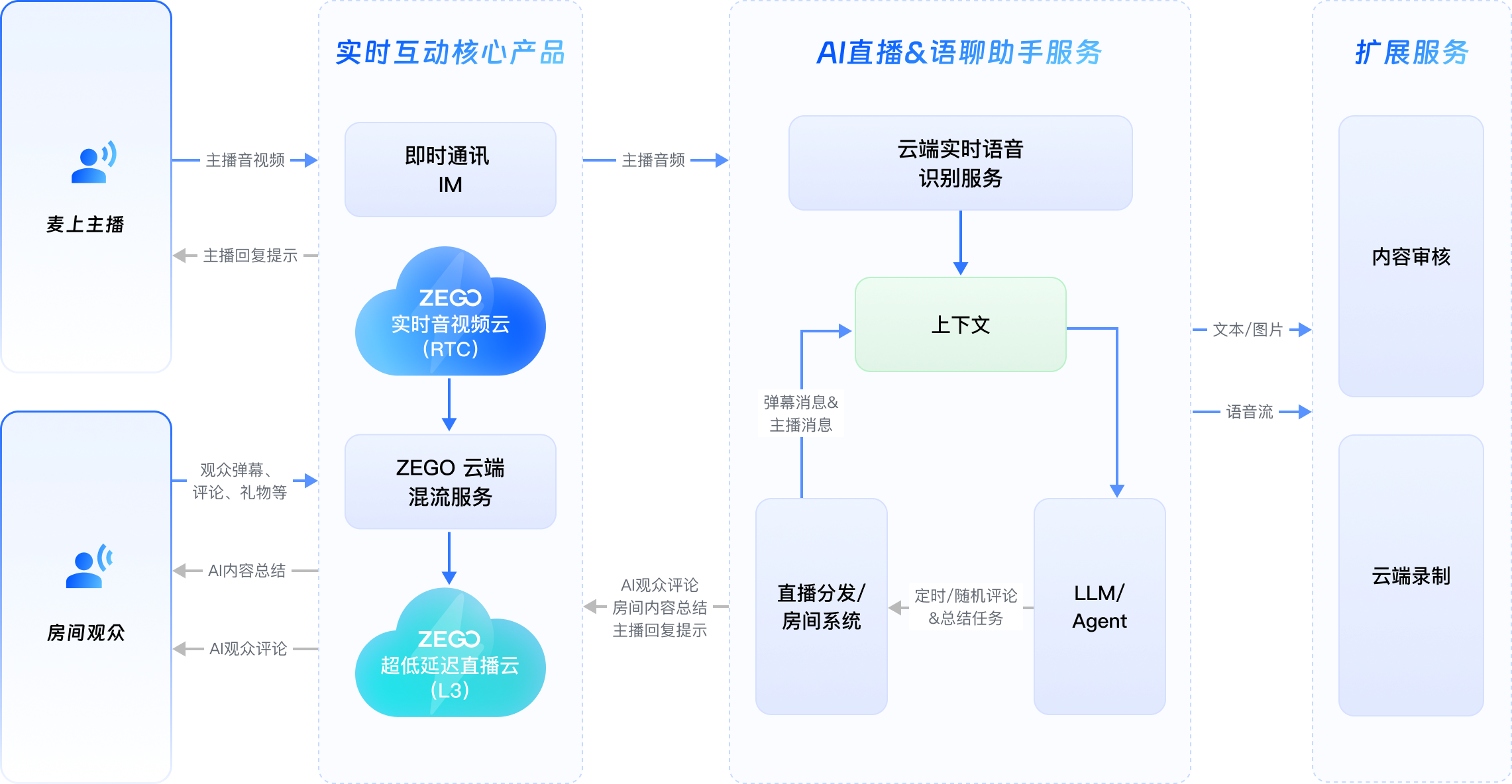
直播间/语聊房AI 互动助手
基于实时音视频RTC、云端实时语音识别 与 LLM大模型,为直播间、语聊房提供全场景 AI 互动助手方案,全方位提升主播开播时长、用户留存与平台活跃度 基于实时音视频RTC、云端实时语音识别与 LLM 大模型,为直播间、语聊房提供全场景 AI 互动助手方案
免费试用



AI 助力解决直播&语聊行业增长困境
消除主播“卡壳”焦虑
帮助新主播 3 分钟破冰
AI 实时推送话题与话术,精准把控直播节奏, 大幅缩短主播孵化周期,提升首月开播存活率
新用户进房秒懂房间话题
留存率提升 10%
AI 实时总结房间话题,帮助新用户快速融入房间,防止进房秒退,提升新用户留存率
7*24 小时带动房间氛围
房间互动提升 30%
AI 观众拟人化回复、评论活跃房间气氛,告别传统机器人的生硬话术,提升用户参与感与观看欲
场景化 AI全面激活直播&语聊生态
主播 AI 助手
快速冷启动
实时话术推荐
基于直播间观众互动反馈,结合主播音频内容与人设,智能匹配场景话题、推送互动话术,化解主播开播冷场难题
智能直播总结
每场直播结束后,AI 基于全场互动内容、观众画像、礼物收益等多维信息生成总结报告,助力主播精准定位问题、优化直播运营策略
房间 AI 助手
提高用户留存
实时话题推送
AI 实时识别房间内语音互动内容,自动生成当前话题精简摘要,新观众进房秒懂话题,零门槛融入
互动发言推荐
针对新进观众,主动推送适配当前话题的发言参考,降低观众开口门槛,带动新用户主动参与互动
AI 虚拟观众
活跃氛围
全时段氛围运营
7×24 小时在线,新观众进房主动热情欢迎,冷场时主动发起话题、救场暖场,让房间全程「活」起来
新手主播专属伴播
聚焦新主播与小主播,贴合主播内容话题,通过专属伴播引导与正向激励,拉升主播开播时长,带动观众活跃度
直播间字幕&翻译
支持主播与观众语音实时转写文字字幕,覆盖多语种实时互译,打破语言壁垒,降低非母语观众理解门槛,助力平台拓展国际化受众
免费试用
全方位核心技术优势
智能成本优化 基于场景按需启用语言识别能力,深度融合实时音视频全链路,较传统方案节省 50% 以上识别成本 基于场景按需启用语言识别能力,较传统方案节省 50% 以上识别成本
精准识别人声 综合识别准确率超 95%,可消除 400+ 场景环境噪声与 99% 回声干扰,复杂场景仍保持稳定识别精度 综合准确率超 95%,消除 400+ 场景噪声及99% 回声,保持高精度
超低延迟识别 端到端 ASR 识别延迟低至 600ms,与 RTC 实时音视频能力深度协同,毫秒级响应主播与观众的实时对话互动 端到端ASR延迟600ms,与RTC深度协同,毫秒级响应实时对话
多语种识别 兼容腾讯、阿里、微软等国内/外主流语音识别厂商,满足全球化场景下的语音识别需求 兼容腾讯、阿里、微软、OpenAI Whisper等多语种模型,适配全球化
全链路合规防护 一站式多模态内容审核服务开箱即用,全流程保障直播、语聊场景的内容合规与业务安全 一站式多模态内容审核开箱即用,保障直播语聊合规与安全
多端平台兼容 全面覆盖 APP/H5/PC 等多终端,深度适配 15000+ 设备型号,实现跨端一致体验与极简快速接入 覆盖APP/H5/PC等多终端,适配15000+型号,跨端一致快速接入
简单4步,探索新可能
从方案选择到上线运营,我们提供全流程的专业服务

01 业务探索
根据业务需要选择合适的方案
根据业务需要选择合适的方案

02 方案设计
技术专家设计规划成熟方案
技术专家设计规划成熟方案

03 服务接入
技术团队 7*24小时提供协助
技术团队 7*24小时提供协助

04 运营支撑
提供可靠的质量分析产品运营
提供可靠的质量分析产品运营




- 接入问题咨询专属技术支持,方便发送截图、代码,更快排查问题报价咨询专属商务对接,报价方案沟通


企微沟通


在线咨询


400电话